by Laurence | Feb 26, 2008 | Local search
Not long ago I was talking with Gib Olander from Localeze, our main data supplier. The topic was local data, and how weird it can be: Some things look like they must be mistakes—except they’re not.
Gib’s example was a place that sells custom rims and also cellphone service. If you saw the business listed under both categories, you might figure one was wrong. But Gib can show you a photo of Cell ‘n’ Wheels that proves otherwise.
I laughed. The example wasn’t so terribly outrageous, and Localeze certainly has an interest in promoting this idea. 🙂 Yet at the same time, I happened to know of a much better illustration.
I get my hair cut at a barber’s shop that also sells seafood. Oysters, specifically. During the holiday season it does a roaring trade in hams, too; they’re piled into a shopping cart by the door. No one seems to mind buying dinner from a place that can get ankle-deep in human hair.
Whatever about rims and phones, I’d definitely suspect an error if my search for [oysters] near [Leesburg, VA] returned Plaza & Tuffy’s Barber Shop as the top result. But it’s the only place in Leesburg that advertises oysters on a sign:

I shot this photo right before getting a haircut. When I went inside, my barber Bobby asked why I had been taking pictures. I told him I had a friend in Chicago who didn’t believe that a barber shop also sold seafood.
“We’re still country here,” he replied. “You tell him that.”
It got me to thinking: In reviewing YellowBot last year, I included a screengrab of something I portrayed as an error—YellowBot’s tags said that a hair-removal place here in Leesburg also sells bail bonds.
Perhaps I was too hasty in calling it a mistake?
by Laurence | Sep 19, 2007 | Local search
Yellow Pages folks surely do love structure — especially when it comes to data. Here at the latest Kelsey conference, where YP folks abound, the only good datum is a structured datum.
Consider the title of yesterday’s most interesting panel:
Building a Better Database: Acquiring Content in a Dysfunctional Environment
The title is a bit grad school, but “dysfunctional” is a strong word that caught my eye. Here it mostly means “resistant to structure.”
And them’s fightin’ words in the world of Yellow Pages.
By now I’ve gone to a bunch of YP-oriented conferences. All of them featured a discussion about how to gather structured data. But I’m starting to suspect that this isn’t the most important problem to solve — and not just because these conference discussions never go anywhere.
Here’s my thinking:
In what a YPer would call a functional environment, every business location, small or large, would authorize a regularly updated master version of its “attributes” (hours, certifications, parking facilities, etc.), and would post this information in some microformat on its Web site, or supply it directly to each data vendor, or send it to an industry-wide data clearinghouse that’ll probably never exist.
In addition, lots of other data sources — licensing bodies, rating sites, whatever — would distribute structured information that’s already normalized and can be correlated perfectly to these master records.
All this data would then be collated by data vendors such as Localeze and sold to Web companies such as Google or, for that matter, Loladex.
Finally, the Web companies would build applications that use the structured data for searching by consumers (input) and display to consumers (output).
This worldview may be summarized thus:
More structured data in → Better answers out.
Or as Marchex‘s Matthew Berk (who’s a smart guy) said at the panel here: “We think local search is about structured search.”
Berk gave a very good example, which I also use when discussing Loladex: If you’re looking for a doctor, you need to know whether he takes your insurance. That’s true, without a doubt.
But here’s the problem I have:
The majority of information available about any company, and particularly about any small company, will never be structured. It’ll exist only on the general Web, where it must be searched on its own terms — that is, as unstructured text.
To me, this suggests that the most pressing data problem isn’t how to gather more structured data, but how to search unstructured data (on Web pages) and return structured answers.
I live on both sides of this equation, by the way. My wife runs a small cookie bakery, and I’m in charge of distributing her data to online sources.
Because of my background, I’m more informed and motivated than most small business owners. And yet, to be honest, just keeping her Web site up-to-date is a chore. On Yelp right now, I’m sorry to say, her hours are incorrect. I should update it, but I just haven’t.
Accuracy on our own Web site is always my #1 priority, because that’s our official voice. Also it’s where most people land when they search for “Lola Cookies.”
Keeping Yahoo Local accurate is on my list, too, but it’s lower down. Ditto Google and YellowPages.com and the other big sites.
I never think about the data vendors one layer back, like InfoUSA, unless they happen to call the store. (Which InfoUSA does, to its credit.)
Meanwhile, plenty of interesting and searchable information about the bakery exists in other places on the Web, in formats that aren’t even addressed by the concept of “attributes.”
A TV broadcast from the bakery aired live on the local morning news recently, for instance. If you watched the show, you might search for us with a term like “fox 5 cookies virginia.” Where does that fit in the world of structured data?
I raised this general issue at yesterday’s panel. What were the panelists doing about this wealth of unstructured Web data, which right now is the dark matter of the local-search universe?
The answer I got was, basically, “Not much.”
Most panelists said they do only highly targeted crawls, focusing on sites that have structured data that can “extend or validate” their own data, in the words of Localeze’s Jeff Beard. An example might be the site of a professional group such as the American Optometric Association.
No panelist was ready to start indexing the sites of individual businesses, or locally focused blogs, or any other sites that are unstructured but potentially rich in content.
The only (mild) exception was Erron Silverstein of YellowBot, who also said his company limits itself to targeted crawls — but included local media, such as newspapers, among his targets.
A few players are indexing the broader Web and then associating pages with specific businesses (which is the important part). Most notable are Google and Yahoo, who do it for their local search products.
Of course, they’re already indexing the entire Web. It’s less of a stretch for them.
Google and Yahoo also buy structured data from InfoUSA, Localeze and others, so it’s not like such data is obsolete. But they’re getting the same info directly from some businesses, and those updates are likely more timely, more accurate, and more complete.
Meanwhile, their Web indices are opening up a realm of data that traditional vendors like Acxiom — represented by Jon Cohn on yesterday’s panel — simply don’t care to address.
I suspect that, sooner than you’d imagine, Google and Yahoo will be buying structured data not so that users can search it directly, but for two less-flattering reasons:
- To help find Web pages they can associate with each business
- To fill ever-smaller gaps in the coverage that results from #1
Matthew Berk of Marchex argued that a good local search must be structured to “help someone walk down the decision trail” by using filters to narrow their search progressively:
I need a orthopedist in Boston … in the Back Bay … who accepts United Healthcare.
I think users are more likely to learn that they can go to Google and type “orthopedist back bay united healthcare” — particularly if it produces a good top result the first time they try.
The burden of local search, it seems to me, is to do something that Google can’t match with an unstructured Web search.
In any case, the search portals will ultimately use their indexed Web pages to extract and cross-check structured data directly. Over time — probably just a couple of years — such automated processes will yield data that’s more current and detailed than anything that’s produced by scanning phone books or calling stores.
The resulting search functionality, integrating both structured and unstructured data, will be sold to other companies as a Web service, and data vendors such as InfoUSA will become irrelevant to local search.
Now that would be a dysfunctional environment for many of the Kelsey attendees.
I’m not sure exactly how companies like InfoUSA and Acxiom should tackle the unstructured Web. It’ll demand a new way of thinking, and probably a new way of selling.
But I’m certain that they ignore unstructured data at their peril.
by Laurence | Apr 26, 2007 | Competitors
While earlier Web 2.0-ish local sites have been dealing with shifting sands, new sites continue to appear. YellowBot is among the latter, and appears to be hanging its hat on tags.
What’s to like about YellowBot? Here are a few things:
- Tags are generally a good idea
- YellowBot has bought nationwide base data from Localeze, which means I don’t have to wait for users to build the site
- It has pre-seeded the tags
- Its location input box has a “suggest” feature that finds matching street addresses in real time, which I haven’t seen before
What’s not to like?
- The pre-seeded tags are a bit hinky, which makes them less useful. In fact, the site’s data seems shaky overall. More on this below.
- Despite the somewhat cool street-address feature, the location “suggestions” work rather weirdly. (Try typing in an address.)
- The site has virtually no user content, even in places where I’d imagine it should, such as its hometown of LA. It has imported some reviews from CitySearch, Zagat and possibly elsewhere, but this seems inconsistent.
- The editorial tone of the site is exclusionary, or possibly just dumb.
The tone is a problem because it’s grating and counterproductive. Maybe I’m getting too old, but I refuse on principle to rate anything as either “rank” (1 star) or “off the heezy” (5 stars):
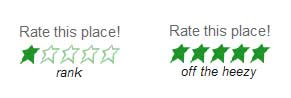 This tone is echoed in the FAQ:
This tone is echoed in the FAQ:
Tags are the flava … of YellowBot.
Mmmm-hmmm.
Is it possible that some people think this is cool? I suppose so, but I can’t imagine YellowBot will get lots of reviews of lawyers and lawn-care services (both of which it touts on its home page today) from such an audience.
Other things will be harder to change. There’s the whole chicken/egg problem of sparse user content; I’ll post soon about that general issue.
And then there’s the data, especially as reflected by tags. I suspect that YellowBot bought its pre-seeded tag content, and the UI really plays it up. Some of it is useful, the rest … not so much.
As a minor example, my brother John runs a hot-dog joint on Hollywood Boulevard in LA. Skooby’s is famous for its hot dogs. YellowBot’s tags for the place, none of which appear to have been contributed by users, are as follows:
Bar Food – Burgers – dining – food – Pizza – restaurant
OK, I forgive the absence of “hot dogs.” But “burgers” and “pizza” are actively wrong. John serves burgers in his quasi-nearby Hermosa Beach location, but YellowBot doesn’t have that listing at all. He doesn’t serve pizza anywhere. If I search for “pizza” and get directed to Skooby’s, I’m being misled.
(I’ll find lasting consolation in LA’s best hot dog, fries and lemonade, of course.)
Some of the YellowBot tags appear to have been entered from Yellow Pages ads. Others are just a mystery. Here’s one medical place in Leesburg, VA:
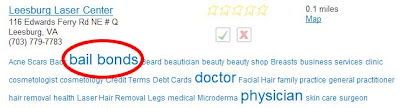
And another:
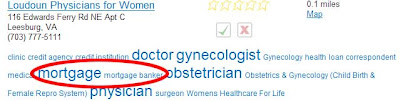
It’s not just tags. The number-two result for a search on “doctor” in Leesburg, VA, is listed as follows:
Jackson River Orthopedics PC
I-64 Exit 21
Leesburg, VA
This business isn’t in Leesburg. I-64 goes nowhere near here.
Unfortunately, I didn’t have to look very hard for examples like this. I’m hoping that YellowBot will work out these kinks before long.